IVaps Framework Overview¶
Setup¶
We are interested in the effect of some binary treatment \(D_i\in \{0,1\}\) on some outcome of interest \(Y_i\). Let \(Y_i(1)\) and \(Y_i(0)\) represent potential outcomes that would be realized if individual \(i\) were treated and not treated, respectively. The observed outcome \(Y_i\) can therefore be written as \(Y_i=D_iY_i(1)+(1-D_i)Y_i(0)\).
The treatment assignment \(D_i\) may be influenced by a binary treatment recommendation \(Z_i\in\{0,1\}\) made by some machine learning algorithm (A). Let the binary variable \(D_i(z)\) be the potential treatment assignment when \(Z_i=z\in\{0,1\}\). \(D_i(z)=1\) indicates that individual \(i\) is treated when the treatment recommendation is \(Z_i=z\). Observed treatment \(D_i\) is therefore \(D_i=Z_iD_i(1)+(1-Z_i)D_i(0)\). Define \(Y_{zi}=D_i(z)Y_i(1)+(1-D_i(z))Y_i(0)\) for each \(z=0,1\).
We impose the exclusion restriction that the treatment recommendation \(Z_i\) does not affect the observed outcome other than through the treatment assignment \(D_i\). This allows us to define the potential outcomes indexed against the treatment assignment \(D_i\) alone.
We consider algorithms that make treatment recommendations based solely on individual \(i\)’s predetermined, observable covariates \(X_i \in \mathbb{R}^p\). Let the function \(A:\mathbb{R}^p\rightarrow [0,1]\) represent the decision algorithm, where \(A(X_i)=\Pr(Z_i=1|X_i)\) is the probability that the treatment recommendation is turned on for individual \(i\) with covariates \(X_i\). The central assumption is that the analysis knows function \(A\) and is able to simulate it. That is, the analyst is able to compute the recommendation probability \(A(x)\) given any input value \(x \in \mathbb{R}^p\). The treatment recommendation \(Z_i\) for individual \(i\) is determined with probability \(A(X_i)\) independent of everything else.
APS¶
In order to understand what causal effects can be learned from the data \((X_i, Z_i, D_i, Y_i)\) generated by the algorithm \(A\), we introduce the Approximate Propensity Score (APS). First, let
where \(B(x,\delta)=\{x^*\in\mathbb{R}^p:\|x-x^*\|\le\delta\}\) is the \(\delta\)-ball around \(x\in {\cal X}\). Here, \(\|\cdot\|\) denotes the Euclidean distance on \(\mathbb{R}^p\). We assume that \(A\) is a \({\cal L}^p\)-measurable function so that the integrals exist.
We then can define APS as follows.
Intuitively, APS at \(x\) is the average probability of a treatment recommendation in a shrinking neighborhood of \(x\). To make common \(\delta\) for all dimensions reasonable, we normalize \(X_{ij}\) to have mean zero and variance one for each \(j=1,...,p\).
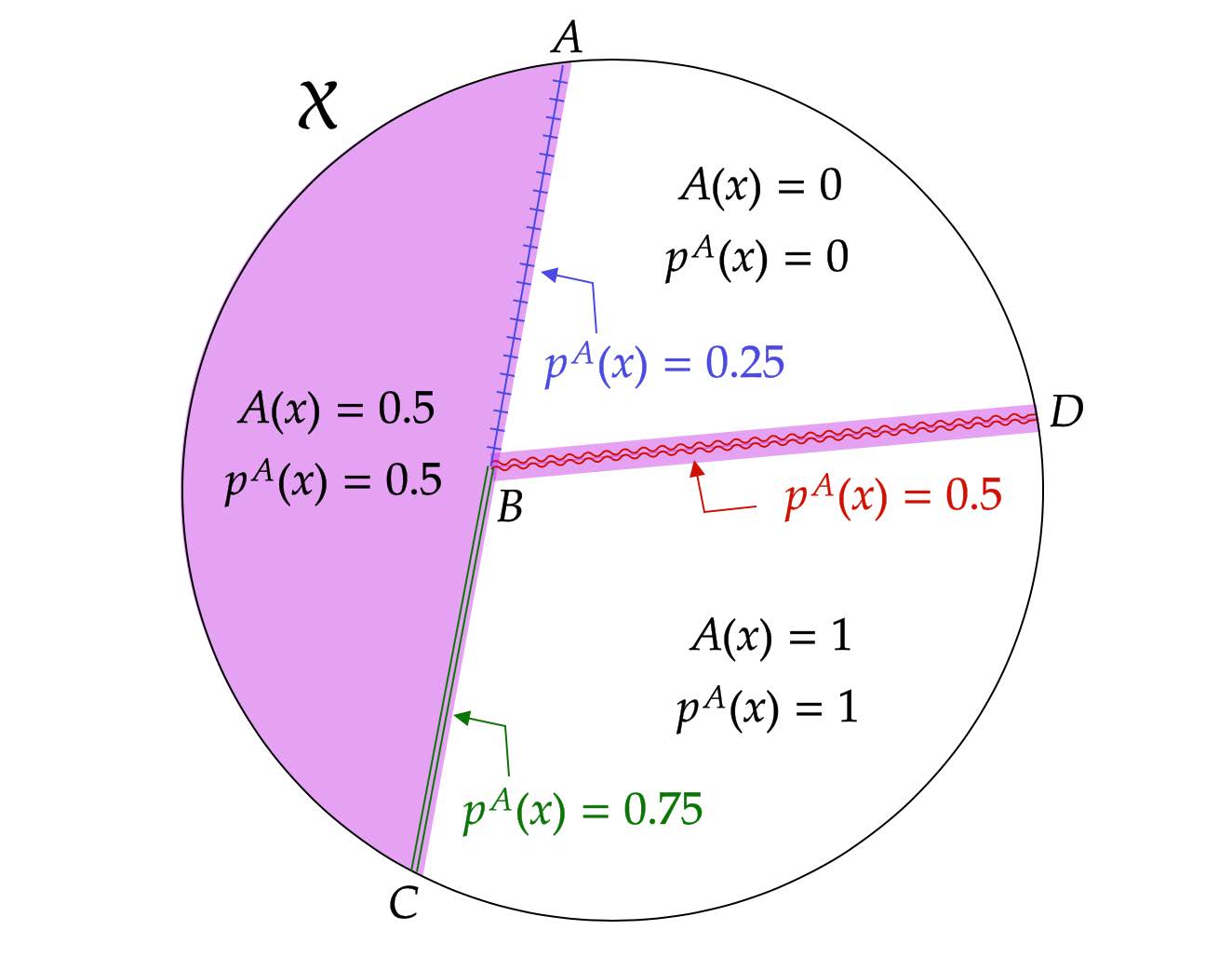
The above image illustrates APS. In the example, \(X_i\) is two dimensional, and the support of \(X_i\) is divided into three sets depending on the value of \(A\). For the interior points of each set, APS is equal to \(A\). On the border of any two sets, APS is the average of the \(A\) values in the two sets. Thus, \(p^{A}(x)=\frac{1}{2}(0+0.5)=0.25\) for any \(x\) in the open line segment \(AB\), \(p^{A}(x)=\frac{1}{2}(0.5+1)=0.75\) for any \(x\) in the open line segment \(BC\), and \(p^{A}(x)=\frac{1}{2}(0+1)=0.5\) for any \(x\) in the open line segment \(BD\).
Identification¶
There are 3 key assumptions that allow us to make our identification claim.
Conditional Independence: \(Z_i \perp\!\!\!\!\perp (Y_i(1),Y_i(0),D_i(1),D_i(0))|X_i\).
Almost Everywhere Continuity: \(A\) is continuous almost everywhere with respect to the Lebesgue measure and \({\cal L}^p({\cal X}_k)={\cal L}^p({\rm int}({\cal X}_k))\) for \(k=0,1\).
Local Mean Continuity: For \(z\in\{0,1\}\), the conditional expectation functions \(E[Y_{zi}|X_i]\) and \(E[D_i(z)|X_i]\) are continuous at any point \(x\in {\cal X}\) such that \(p^{A}(x)\in (0,1)\) and \(A(x)\in \{0,1\}\).
From these 3 assumptions we can make the following identification proposition. Under Assumptions 1-3,
\(E[Y_{1i}-Y_{0i}| X_i=x]\) and \(E[D_i(1)-D_i(0)| X_i=x]\) are identified for every \(x\in \int{{\cal X}}\) such that \(p^{A}(x)\in (0,1)\).
Let \(A\) be any open subset of \({\cal X}\) such that \(p^{A}(x)\) exists for all \(x\in A\). Then either \(E[Y_{1i}-Y_{0i}| X_i \in A]\) or \(E[D_i(1)-D_i(0)| X_i \in A]\), or both are identified only if \(p^{A}(x)\in (0,1)\) for almost every \(x\in A\) (with respect to the Lebesgue measure).
This proposition suggests that by conditioning on APS, A-based treatment recommendations are quasi-randomly assigned. We can thus make use of A treatment recommendations as an instrument for treatment assignment, conditional on APS. There are several methods for applying instrumental variables in estimating causal treatment effects. In this package we follow [1] in applying two stage least squares (2SLS), though it is certainly possible other methods are added in the future.
The details of the estimation procedure are as follows.
Suppose that we observe a random sample \(\{(Y_i,X_i,D_i,Z_i)\}_{i=1}^n\) of size \(n\) from the population whose data generating process is described in Setup.
Consider the following 2SLS regression using the observations with \(p^{A}(X_i;\delta_n)\in (0,1)\):
where bandwidth \(\delta_n\) shrinks toward zero as the sample size \(n\) increases.
Let \(\hat\beta_1\) denote the 2SLS estimator of \(\beta_1\) in the above regression.
The above regression uses true APS \(p^{A}(X_i;\delta_n)\), but it may be difficult to analytically compute if \(A\) is complex. In such a case, we propose a method to approximate \(p^{A}(X_i;\delta_n)\) using brute force simulation. We draw a value of \(x\) from the uniform distribution on \(B(X_i,\delta_n)\) a number of times, compute \(A(x)\) for each draw, and take the average of \(A(x)\) over the draws.
Formally, let \(X_1^*,...,X_{S_n}^*\) be \(S_n\) independent draws from the uniform distribution on \(B(X_i,\delta_n)\), and calculate \(p^s(X_i;\delta_n)=\frac{1}{S_n}\sum_{s=1}^{S_n}A(X_{i,s}^*)\). We compute \(p^s(X_i;\delta_n)\) for each \(i=1,...,n\) independently across \(i\) so that \(p^s(X_1;\delta_n),...,p^s(X_n;\delta_n)\) are independent of each other. For fixed \(n\) and \(X_i\), the approximation error relative to true \(p^{A}(X_i;\delta_n)\) has a \(1/\sqrt{S_n}\) rate of convergence.
This rate does not depend on the dimension of \(X_i\), so the simulation error can be made negligible even when \(X_i\) is high dimensional.
Now consider the following simulation version of the 2SLS regression using the observations with \(p^s(X_i;\delta_n)\in (0,1)\):
\(I_n\) is the indicator that \(A(X_i)\) takes on only one nondegenerate value in the sample. If the support of \(A(X_i)\) (in the population) contains only one value in \((0,1)\), \(p^{A}(X_i;\delta_n)\) is asymptotically constant conditional on \(p^{A}(X_i;\delta_n)\in(0, 1)\). Let \(\hat\beta_1^s\) denote the 2SLS estimator of \(\beta_1\) in the simulation-based regression. This regression is the same as the original structural 2SLS regression except that we use the simulated APS \(p^s(X_i;\delta_n)\) in place of \(p^{A}(X_i;\delta_n)\).
In practice, \(\hat\beta_1^s\) will be the estimated causal treatment effect. Under additional regularity conditions, this estimator is consistent for a well-defined causal effect. The details are ommitted here for brevity. Please refer to [1] for more formal statements and proofs of the method described.
Examples¶
The IVaps method can be applied to a broad swath of algorithms which generate treatment recommendations. Below are a few examples of popular algorithms for which our framework applies.
Supervised Learning¶
Millions of times each year, judges make bail-or-release decisions that hinge on a prediction of what a defendant would do if released. Many judges now use proprietary algorithms (like COMPAS criminal risk score) to make such predictions and use the predictions to support bail-or-release decisions. Kleinberg et al. (2017) also developed another prediction algorithm.
These algorithms fit into our framework as a simple special case. Using our notation, assume that a criminal risk algorithm recommends bailing (\(Z_i=1\)) and releasing (\(Z_i=0\)) to each defendent i. The algorithm uses defendant i’s observable characteristics \(X_i\), includinng criminal history and demographics. The algorithm first translates \(X_i\) into a continuous risk score \(r(X_i)\), where \(r:\mathbb{R}^p \rightarrow \mathbb{R}\) is a function estimated by supervised learning based on past data and assumed to be fixed.
The algorithm then uses the risk score to make the final recommendation:
where \(c\in\mathbb{R}\) is a constant threshold that is set ex ante.
In this case, the algorithm uses the discretized risk score to make the final recommendation:
Suppose that \(r\) is continuous and is continuously differentiable in a neighborhood of \(x\), and \(\frac{\partial r(x)}{\partial x}\neq0\) for any \(x\in{\rm int}({\cal X})\) with \(r(x)=c\). APS for this case is given by
It is therefore possible to identify and estimate causal effects conditional on \(x\) with \(r(x)=c\) and \(x\in{\rm int}({\cal X})\).
Reinforcement Learning and Bandit¶
We are constantly exposed to digital information (movie, music, news, search results, advertisements, and recommendations) through a variety of devices and platforms. Tech companies allocate these pieces of content through reinforcement learning and bandit algorithms. Our method is also applicable to many popular bandit and reinforcement learning algorithms. For simplicity, assume that individuals perfectly comply with the treatment assignment \((D_i=Z_i)\).
Bandit Algorithms
The algorithms below first use past data and supervised learning to estimate the conditional means and variances of potential outcomes, \(E[Y_i(z)|X_i]\) and \(Var(Y_i(z)|X_i)\), for each \(z\in \{0, 1\}\). Let \(\mu_z(X_i)\) and \(\sigma^2_z(X_i)\) denote the estimators. The algorithms then use \(\mu_z(X_i)\) and \(\sigma^2_z(X_i)\) to determine the treatment assignment for individual \(i\).
Thompson Sampling Using Gaussian Priors
The algorithm first samples potential outcomes from the normal distribution with mean \((\mu_0(X_i), \mu_1(X_i))\) and variance covariance matrix \({\rm diag}(\sigma^2_0(X_i), \sigma^2_1(X_i))\). The algorithm then chooses the treatment with the highest sampled potential outcome. As a result, this algorithm chooses the treatment assignment as follows:
\[Z^{TS}_i \equiv arg max_{z\in \{0, 1\}}y(z), ~~A^{TS}(X_i)= E[arg max_{z\in \{0, 1\}}y(z)|X_i]\]where \(y(z)\sim {\cal N}(\mu_z(X_i), \sigma^2_z(X_i))\) independently across \(z\).
The function \(A\) has an analytical expression:
\[A^{TS}(x)=1-\Phi(\dfrac{\mu_0(x)-\mu_1(x)}{\sqrt{\sigma^2_0(x)+\sigma^2_1(x)}})\]where \(\Phi\) is the CDF of a standard normal distribution. Suppose that the functions \(\mu_0\), \(\mu_1\), \(\sigma^2_0\) and \(\sigma^2_1\) are continuous on \({\rm int}({\cal X})\). APS for this case is given by
\[p^{TS}(x)=1-\Phi(\dfrac{\mu_0(x)-\mu_1(x)}{\sqrt{\sigma^2_0(x)+\sigma^2_1(x)}})\]for any \(x\in {\rm int}({\cal X})\). This APS is non-degenerate, meaning that the data from the algorithms allow for causal-effect identification.
Upper Confidence Bound, UCB
Unlike the above stochastic one, the UCB algorithm is a deterministic algorithm, producing a less obvious example of our framework. This algorithm chooses the treatment with the highest upper confidence bound for the potential outcome:
\[\begin{split}\begin{align*} Z^{UCB}_i &\equiv arg max_{z=0, 1} \{\mu_z(X_i)+\alpha(X_i) \sigma_z(X_i)\},\\ A^{UCB}(x) &=\begin{cases} 0 & \ \ \ \text{if $\mu_1(x)+\alpha(x)\sigma_1(x)<\mu_0(x)+\alpha(x)\sigma_0(x)$}\\ 1 & \ \ \ \text{if $\mu_1(x)+\alpha(x)\sigma_1(x)>\mu_0(x)+\alpha(x)\sigma_0(x)$}, \end{cases} \end{align*}\end{split}\]where \(\alpha(x)\) is chosen so that \(|\mu_z(x)-E[Y_i(z)|X_i=x]|\leq \alpha(x) \sigma_z(x)\) at least with some probability, for example, \(0.95\), for each \(x\).
Suppose that the function \(\mu_1-\mu_0+\alpha (\sigma_1-\sigma_0)\) satisfies the conditions imposed on risk score function \(r\) in the Supervised Learning example with \(c=0\).
APS for this case is given by
\[\begin{split}p^{UCB}(x)=\begin{cases} 0 & \ \ \ \text{if $\mu_1(x)+\alpha(x)\sigma_1(x)<\mu_0(x)+\alpha(x)\sigma_0(x)$}\\ 0.5 & \ \ \ \text{if $\mu_1(x)+\alpha(x)\sigma_1(x)=\mu_0(x)+\alpha(x)\sigma_0(x)$ and $x\in {\rm int}({\cal X})$}\\ 1 & \ \ \ \text{if $\mu_1(x)+\alpha(x)\sigma_1(x)>\mu_0(x)+\alpha(x)\sigma_0(x)$}. \end{cases}\end{split}\]This means that the UCB algorithm produces potentially complicated quasi-experimental variation along the boundary in the covariates space where the algorithm’s treatment recommendation changes from one to the other. It is possible to identify and estimate causal effects across the boundary.
Unsupervised Learning¶
Customer segmentation is a core marketing practice that divides a company’s customers into groups based on their characteristics and purchasing behavior so that the company can effectively target marketing activities at each group. Many businesses today use unsupervised learning algorithms, clustering algorithms in particular, to perform customer segmentation. Using our notation, assume that a company decides whether it targets a campaign at customer \(i\) (\(Z_i=1\)) or not (\(Z_i=0\)). The company first uses a clustering algorithm such as \(K\) means clustering or Gaussian mixture model clustering to divide customers into \(K\) groups, making a partition \(\{S_1,...,S_K\}\) of the covariate space \(\mathbb{R}^p\). The company then conducts the campaign targeted at some of the groups:
where \(T\subset \{1,..,K\}\) is the set of the indices of the target groups.
For example, suppose that the company uses \(K\)-means clustering, which creates a partition in which a covariate value \(x\) belongs to the group with the nearest centroid. Let \(c_1,...,c_K\) be the centroids of the \(K\) groups, and define a set-valued function \(C:\mathbb{R}^p\rightarrow 2^{\{1,...,K\}}\), where \(2^{\{1,...,K\}}\) is the power set of \(\{1,...,K\}\), as
If \(C(x)\) is a singleton, \(x\) belongs to the only group in \(C(x)\). If \(C(x)\) contains more than one indices, the group to which \(x\) belongs is arbitrarily determined.
APS for this case is given by
and \(p^{CL}(x)\in (0,1)\) if \(|C(x)|\ge 3\), \(x\in \partial(\cup_{k\in T} S_k)\) and \(x\in {\rm int}({\cal X})\), where \(|C(x)|\) is the number of elements in \(C(x)\), and \(\partial(\cup_{k\in T} S_k)\) is the boundary of \(\cup_{k\in T} S_k\). Thus, it is possible to identify causal effects conditional on observables \(x\) on the boundary \(\partial(\cup_{k\in T} S_k)\).